
基于图像搜索引擎的图文无关识别方法

一、摘要
目前互联网知识问答社区正在蓬勃发展,例如国外的quora,国内的悟空问答、知乎。一般来说,在这些知识问答社区,答案排序算法会预测用户对于不同答案的偏好进行排序,其排序模型往往会考虑答案在一段时间内的点击率、点赞率、分享率、用户平均阅读时间等进行排序。大部分情况下,这样的排序算法是比较有效的,也能筛选出符合用户需求的答案。 但有时候这样的算法也会被一些内容迷惑,比如有一些答案放了一些比较博眼球的内涵图片,吸引了大量用户的点击和点赞,但是并没有提供更多有价值的信息,这样对于正常的内容来说就不太公平了。这是一种典型的图文无关案例。所谓的图文无关指的是内容(此算法主要在悟空问答上进行尝试,后面用答案代称此处的内容)中的配图、和内容文字不匹配,比如一个很严谨的历史问题,配了一个美女图片,或者一个科技领域的答案,配了一张风景图片。这样的答案往往点击率不低,虽然内容可能写得还可以,但是相对于没有图片的答案来说,是相当不公平的。对于社区来说,这样乱配图会严重带坏社区的氛围。
传统的图文无关内容识别方法往往基于图像识别技术并针对某一类特定问题,比如色情图片识别,可以识别出有色情意味的图片,如果用户发布的文字内容没有色情词,就可以认定为图文无关。再比如OCR(Optical Character Recognition) 技术,可以从图片中抽取出现在图片中的文字信息,然后通过比对抽取的文字信息和用户发布的文字内容,确认是否图文无关。另外对于特别是大型的网络社区,由于用户发布的图文无关内容五花八门,我们需要一种通用方法,能够低成本的解决各种图文无关问题。一个比较容易想到的方法是用近年来不断成熟的图像分类技术,对图像分类然后再用文本分类器判别用户发布的文字内容是否和图片属于同一类,但是实际中缺乏一个和图像分类对应的文本分类体系(典型的图像分类标签包括:猴子、猫、人物等;而文本内容的分类标签的例子包括:历史、财经、股票、互联网等),导致这种方法理论上可行,实际上效果很差。
由于在问答社区中,作者配图大部分是通过搜索引擎去搜索图片,粘贴过来,所以答案中的配图,大部分都来至于互联网;本文提出了一种基于图像搜索引擎的图文无关内容通用识别方法,实际应用中识别准确率和准确率都非常高。
二、算法流程
搜索引擎天生的优势就是索引了全网的内容,拥有丰富的资源,本算法也是充分利用搜索引擎这一特性来获取图片的关键信息。给定图片G和文字文本W,该方法的流程如下:
把图片G上传到图片搜索引擎,查找图片的来源;
提取前K个来源的网页title;
将此K个title分词以及词性标注,合并得到图片的关键词描述M;
计算M和W的相关性,得到一个打分S;
如果相关性打分S低于一个阈值,则认为图片G和文本W不相关。
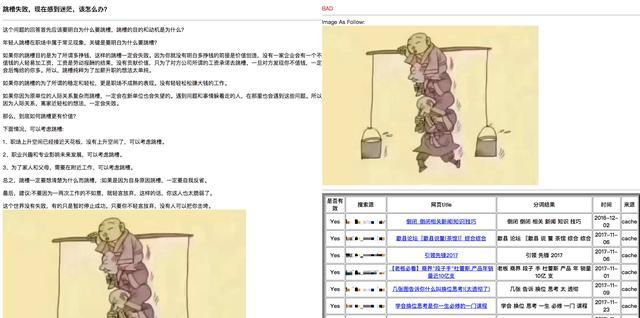
本质上,该方法是利用图片搜索引擎查找到用户给内容配图时,通过搜索引擎关键字搜索到的图片的网页;通过这些网页来获取该图片的关键描述信息,再对比这些关键信息,来达到判断是否图文相关。
三、相关性计算
在本文提及的方法中,我们采用GBDT算法来训练一个相关性打分模型;特征主要有:
命中关键词个数;
关键词中名词个数;
IDF;
BM25;
平均命中个数;
同义词命中个数;
等等……
四、训练集构造
文中涉及相关性打分采用的是GBDT训练的打分模型,必然涉及到训练集如何构造,经过分析,具有高分享量的回答,以及高评级作者写的回答,配图都比较相关;我们选择这一部分回答并去掉首尾两张图作为正样本;这些图随机匹配一个回答作为负样本。
五、实验效果
随机sample悟空问答被识别出来的107个答案,通过人工评测,准确率达到0.9。